数论函数求和(上)
本文共约 8000 字。
Key Words:积性函数,狄利克雷卷积,莫比乌斯反演,gcd 卷积,线性筛,整除分块,整除差分,狄利克雷前缀和,快速卷积性函数
基本概念
数论函数
数论函数:定义域为正整数的函数。
完全积性函数:若数论函数
满足 ,则称为完全积性函数。 积性函数:若数论函数
满足 ,则称为积性函数。
显然完全积性函数是积性函数。对于积性函数,有
- 熟悉的完全积性函数
积性分解
对于积性函数
,给出质因数分解 。则有 推论:只需质数幂处的取值,就足可以确定一个积性函数。
由积性的定义易证。
狄利克雷卷积
两个数论函数
的狄利克雷卷积为一个新的数论函数,记作 。定义
例如
狄利克雷卷积的运算性质
交换律:
。 结合律:
。 单位元:记数论函数
满足 。对于任意数论函数 ,都有 。
以上性质根据定义容易证明。
狄利克雷卷积逆
两个数论函数
满足 ,则称 互为逆元。
狄利克雷卷积的计算
引理(约数/倍数个数和)
对于每个
,枚举其在 中的倍数(或因数),复杂度为 。
证明:枚举倍数:总枚举次数
枚举因数:在“枚举倍数”中,
乘法的计算:给出
的前 项,计算 的前 项。 直接用定义式计算。为了方便,可以转枚举因数为枚举倍数。复杂度
。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
void mul(int *f, int *g, int *h, int n) {
// 计算 f,g 狄利克雷卷积的前 n 项, 存入 h 中.
// h 初值为 0.
for (int x=1; x<=n; x++)
for (int y=1; x*y<=n; y++)
h[x*y] += f[x]*g[y];
}
int main() {
int N = 8,
f[N+1] = {0, 1, 4, 5, 2, 7, 6, 3, 8},
g[N+1] = {0, 3, 1, 6, 7, 2, 8, 4, 5},
h[N+1] = {0, 0, 0, 0, 0, 0, 0, 0, 0};
mul(f, g, h, N);
for (int i=1; i<=N; i++)
printf("%d ", h[i]);
return 0;
}
/* ----- output: -----
3 13 21 17 23 55 13 59
------------------- */乘法逆元的计算:给出
满足 , 满足 ,求 的前 项。 显然有
。假设对于 已求出 ,欲求 ,有如下递推式 复杂度
。 在实现时,也可以转枚举因数为枚举倍数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
void inv(int *f, int *g, int n) {
// 计算 f 狄利克雷卷积逆的前 n 项, 存入 g 中.
// f[1]=1, g 初值为 0.
g[1] = 1;
for (int x=1; x<n; x++)
for (int y=2; x*y<=n; y++)
g[x*y] -= g[x]*f[y];
}
int main() {
int N = 8,
f[N+1] = {0, 1, 4, 5, 2, 7, 6, 3, 8},
g[N+1] = {0, 0, 0, 0, 0, 0, 0, 0, 0};
inv(f, g, N);
for (int i=1; i<=N; i++)
printf("%d ", g[i]);
return 0;
}
/* ----- output: -----
1 -4 -5 14 -7 34 -3 -56
------------------- */
积性的保持
积性函数和狄利克雷卷积是本节最重要的两个概念,它们有如下的密切关系。
- 定理(狄利克雷卷积的积性)
- 两个积性函数的狄利克雷卷积仍是积性函数。
- 积性函数的逆仍是积性函数。
证明:
(定理一)设有两个积性函数
设
第二行,由于
第四行,我们使用
(定理二)设有积性函数
使用归纳法。当
除此之外,常见的函数运算还有点积和复合。
点积:两个数论函数
的点积为一个新的数论函数,记作 。其满足 复合: 给出数论函数
,其中 的值域为正整数,两者的复合 记作 。
对于积性函数
一个常见的特例:
莫比乌斯反演
抽象的长篇大论令人口干舌燥,在上一小节中没有引入任何一个具体的积性函数!现在到了尝尝具体例子的时候,我们隆重介绍:
莫比乌斯函数
将
的狄利克雷卷积逆元记为 ,称作莫比乌斯函数。 即
,展开得
根据“积性函数的逆是积性函数”,
可以用前文的求逆法
为了进一步了解性质,尝试写出
根据
- 对于
, ,归纳可证得 。
综上,总结出一般公式
线性筛
线性筛可以在
其算法流程如下:
- 枚举
- 若
没有标记,说明 是质数,将其加入质数集合 - 从小到大枚举
,记 - 标记
- 记
的最小质因子为 - 若
,退出循环
- 标记
- 若
- 定理:线性筛会标记每个合数恰一次,且得到其最小素因子。
证明:若
可以发现我们枚举的是
线性筛常用于求积性函数的前缀值。以
1 |
|
对于其他更复杂的积性函数
记
例题 4.2.1. 「Coprime Box」
维护一个正整数集合
,支持如下三个操作: - 向
中加入 。 - 从
中删除 。 - 给出
,求 。
给出
,保证 ,操作总个数为 。 。 - 向
Solution:
首先介绍常用技巧:拆解
- 引理:
根据该引理:
回到例题,将询问中的
记
记
总复杂度
注:如果保证每个数字只出现一次,复杂度
整除
接下来,我们将由狄利克雷卷积自然地引导出整除,并介绍针对整除进行计算的方法。
整除分块
例题 4.2.2. 「整除求和」
给出
,求下列式子的值 。
Solution:下面我们将给出一个解决该问题的算法,称为整除分块算法。
引理
对于
, 的本质不同的取值只有 个。
证明:当
当
注意到
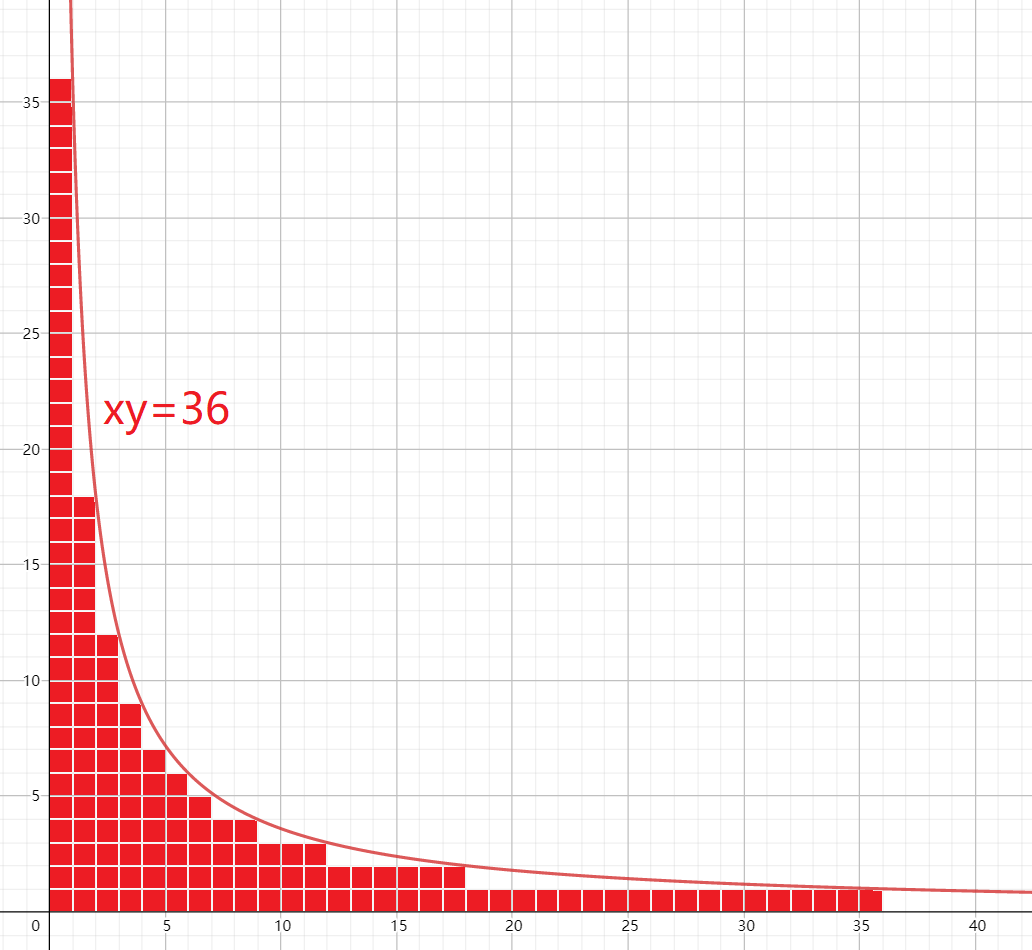
考虑如何快速计算
- 声明变量
,令 ,当 时继续循环。 - 记
,得到一个等值连续段 。 - 令
加上 ,即这一段的总和。 - 令
为 ,前往下一段。
- 记
1 |
|
现在你已经对整除分块有了基本的认识,它所揭示的结构是相当重要的。接下来,我们来看看它和莫比乌斯反演是怎样初次走到一起的,它们的经典之作是:
例题 4.2.3. 「Coprime Matrix」
给出
求下列式子的值 多组数据, , 。
Solution:
该和式中出现了整除,且有两个被除数。
具体算法如下:
- 声明变量
,令 ,当 时继续循环。 - 记
即最近的分段点,得到一个等值连续段 。 - 令
加上 ,即这一段的总和。其中需要预处理 的前缀和以计算部分和。 - 令
为 ,前往下一段。
- 记
复杂度为
1 |
|
- 例题 4.2.4. Luogu4318 完全平方数
整除与差分
针对单个“被除数”计算答案时,可以采用整除分块。当我们需要对被除数为
观察相邻被除数在差分时的表现,有:
定理(整除的性质)
,且此时 。
证明:
时: 恰好整除, 会向下取整,导致 。 时:设 ,则 ,故 。
例题 4.2.5.
对于(正整数)序列
,若 ,则称这个序列是好的。 对
,分别求值域为 的好序列个数。 。(无需考虑输出耗时)
Solution:记值域为
若对每个
对答案数组
线筛
复杂度
1 |
|
常见积性函数
- 完全积性函数
. .
- 积性函数
的因数个数 的因数的 次方和 中与 互质的数的个数
欧拉函数
- 定理:欧拉函数是积性函数。
证明:用
由此可得
接下来考虑欧拉函数的计算,根据定义不难得到
记
记
此式可用于线性筛。
例题 4.2.6.
仪仗队(简化版) 给出
,求 。
Solution:
不难发现这是【例题4.2.3】的子问题,但现在
注意到求和是对称的,可以将
这一结果无疑更加简洁,只需筛出
根据【例题4.2.3】的最终结果
我们仅通过机械的公式推导发现了
通过标准化(往往是代数化),足够强大的系统理论可以代替观察力。
- 例题 4.2.7. Luogu4449 于神之怒加强版
除数函数
根据定义可知
显见
接下来考虑除数函数的计算。对于
记
再重申一下前面已经知道的小结论
- 例题 4.2.8. Luogu6060 [加油武汉] 传染病研究
高维变换
在前面的四个小节中,我们从积性和卷积出发建构了较为完善的分析体系。在这一节,我们将揭示“整除”本质上是无穷维偏序,进而说明莫比乌斯反演和其他领域的联系。
唯一分解与高维点表示
记
可以将数列视作高维点,根据高维点的偏序,定义
高维点视角下的整除关系
。 (逐位取 ) (逐位取 )
偏序求和
对数论函数
,定义 约数求和:
倍数求和:
偏序差分
定义约数差分
满足 ,即“约数求和”的逆操作。类似地定义倍数差分 。
约数差分与倍数差分统称为莫比乌斯反演。
以高维点的视角来看,约数求和是高维前缀和,倍数求和是高维后缀和。两者的计算都容易通过枚举倍数(因数)
(根据转置原理)将上述两个算法的影响倒序恢复,即可得到计算约数差分、倍数差分的算法。
1 | void Lsum(int *f, int n) { |
约数差分、倍数差分与
的关系 约数差分:
。 倍数差分:记
,则
证明:
(约数差分)易知
(倍数差分)
(法一)观察
(法二)
gcd 卷积
给出函数
下面给出一个计算
先求出
尤其注意
只需计算
如果你了解位运算卷积,注意到
- 例题 4.2.9. Luogu2714 四元组统计
四变换的快速计算
我们已经知道,如果将正整数质因数分解后视作高维点,约数求和与倍数求和分别可以看做高维前缀和与高维后缀和。高维前缀和相当于对每一维依次做前缀和。于是,对每个维度(质数)逐个做前缀和,即可计算因数求和。
1 | void Lsum(int *f, int n) { |
复杂度为
快速卷积性函数
给出数论函数
首先将
正确性不难理解,
综上,我们将卷一个积性函数转化为了卷
- 例题 4.2.10. Luogu6222 「P6156 简单题」加强版(加强版)